The AI Interview Arms Race: Why Detection Will Always Lose
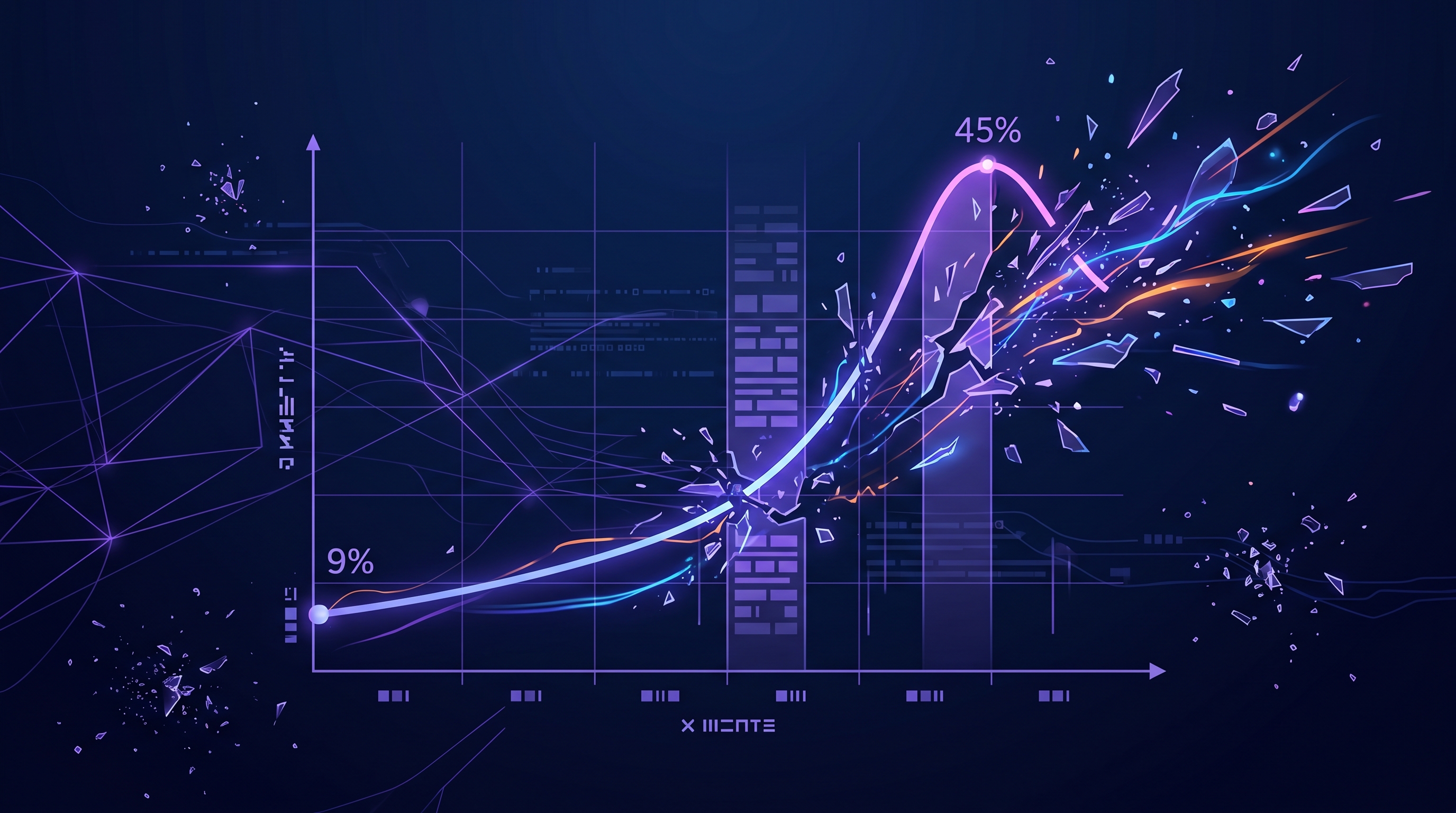
38% of technical interviews triggered cheating flags in a recent analysis of 19,368 interviews. The rate doubled in six months. The detection approach is losing - and it is going to keep losing.

Thirty-eight percent.
That is the percentage of technical interviews that triggered cheating flags in a recent analysis of 19,368 interviews conducted between July 2025 and January 2026. The rate started at 9% in July and hit 45% by September. In six months, it more than doubled.
These numbers come from Fabric, a company that builds AI-powered cheating detection for interviews. Their own data tells a story they probably did not intend: the detection approach is losing.
And it is going to keep losing.
The arms race nobody can win
Here is how the AI interview cheating cycle works:
Companies deploy technical assessments. Candidates use AI tools to solve them. Companies add proctoring and cheating detection. Candidates find workarounds. Companies add more sophisticated detection. Candidates find more sophisticated workarounds.
The tools are already here. Purpose-built "interview co-pilots" run on a second screen or phone. They listen to the interviewer's question, generate an answer in real time, and feed it to the candidate through a nearly undetectable interface. New ones launch every month.
For every detection method - gaze tracking, response timing analysis, clipboard monitoring, browser lockdown - there is a countermeasure. The detection industry is building increasingly complex walls around a fundamentally broken format.
Google and McKinsey responded by going back to in-person interviews. That is not a solution. That is a retreat. It does not scale, it limits your talent pool to people who can travel, and it still does not tell you how someone works with AI tools they will use every day on the job.
Why "cheating" is the wrong frame
Here is what the detection industry gets wrong: they have defined the problem as cheating.
But what is "cheating" in a technical interview? Using a tool that every engineer uses every day at work? Prompting an AI to help solve a problem - exactly the way they will solve problems on your team?
When 38% of candidates are "cheating," maybe they are not cheating. Maybe the test is wrong.
Think about it from the candidate's perspective. They use Claude and GPT every day to write code, debug issues, and architect systems. They walk into an interview that bans these tools and asks them to solve algorithmic puzzles from memory. The test feels irrelevant because it is irrelevant.
The real question is not "how do we catch candidates using AI?" It is "what should we be measuring in a world where every engineer uses AI?"
The signal problem
Traditional technical interviews measure a few things well: algorithmic knowledge, syntax recall, performance under pressure. For 20 years, these were reasonable proxies for engineering ability.
They are not anymore.
When I was CTO at LSports, scaling from 15 to 120 engineers, I could feel the interview signal degrading in real time. Candidates who aced the technical screen struggled in the role. Candidates who stumbled in interviews turned out to be exceptional engineers. The correlation between interview performance and job performance was breaking.
By 2024, it was broken.
The skills that separate a great engineer from an average one in 2026 are fundamentally different from what they were five years ago: Can they decompose a complex problem into AI-addressable components? Can they evaluate whether the AI's output is correct, efficient, and maintainable? Can they recognize when the AI is confidently wrong? Can they integrate multiple AI-generated components into a coherent system? Can they explain and defend decisions they made during the process?
None of these skills are measured by a LeetCode screen. None of them are measured by banning AI and watching someone write code from memory. And none of them are detected by cheating prevention software.
A different architecture
What if, instead of trying to prevent candidates from using AI, you built an environment that embraces it?
Give them a real IDE with real AI tools - Claude, GPT-4o, Gemini. Give them a real engineering task. Let them work the way they actually work on the job.
Then capture everything. Every keystroke, every AI prompt, every pause, every course correction. The full behavioral timeline of how they approached the problem.
Now you have something no interview conversation - human or AI-led - can give you: a replay of how the engineer actually thinks.

This is the core idea behind Eval-X. Instead of testing candidates in an artificial environment and then trying to detect when they break the rules, we put them in a real environment and watch how they work.
There is nothing to "cheat" on because there are no restrictions to circumvent. The AI tools are part of the test. What we are evaluating is the human judgment layer: the decisions, the critical evaluation, the architectural thinking, the ability to drive AI rather than follow it.
Multi-dimensional signal
When you capture the full behavioral timeline, you can score across dimensions that actually predict job performance:
Problem Framing: Did they think before they coded? Did they understand the problem, or did they immediately dump it into an AI prompt and hope for the best?
AI Usage Quality: This is the dimension nobody else measures. Did they drive the AI or follow it? Did they evaluate its output critically? Did they iterate on prompts when the first result was wrong?
System Design: Did they make real architectural choices? Or did they just optimize whatever the AI suggested first?
Code Quality: Not syntax - the AI handles syntax. Does this code survive change? Could another engineer pick it up?
Adaptability: What happens when the requirements change mid-task? Panic, or clean pivot?
Explanation: Can they walk through their own code? Or does the conversation reveal it was never really theirs?
This is a multi-dimensional evaluation framework - starting with these six dimensions and expanding as AI-era workflows evolve. Because the skills that matter will keep shifting, and any fixed assessment will become stale.
The economic case
The cost of the detection arms race is not just the tools and the engineering time to implement them. It is the false positives and false negatives in your hiring pipeline.
False positives: candidates who pass your screen (with or without AI help) but cannot perform on the job. CTOs I talk to estimate a 30-50% false positive rate with current processes. At $150K+ fully loaded cost per senior engineer, plus 3-6 months of lost productivity before the mis-hire is identified, the math is brutal.
False negatives: candidates who would be excellent engineers but fail your artificial, no-AI assessment. These are often your best prospects - engineers who have fully integrated AI into their workflow and do not perform well when forced to work without it.
Every dollar spent on cheating detection is a dollar not spent on better signal.
Where we are headed
The companies that figure this out first will have a structural advantage in engineering talent. They will hire engineers who are actually good at the job as it exists today - not the job as it existed in 2020. They will have lower false positive rates, shorter time-to-productivity, and stronger engineering teams.
The companies that keep investing in the detection arms race will keep running on a treadmill. Faster detection, faster workarounds, higher costs, same bad signal.
The interview is not broken because candidates are cheating. It is broken because the format tests the wrong things. The fix is not better walls. It is a better architecture.
Sources
Frequently asked questions
If 38% of candidates are cheating, should we not catch them?
When 38% of candidates use the same tools they use at work, the test is wrong, not the candidates. The real question is: what should we measure when engineers work with AI daily?
Is in-person interviewing the solution to AI cheating?
No. In-person interviews do not scale, limit your talent pool to people who can travel, and still do not measure how engineers work with AI tools they will use daily on the job.
What is the alternative to detection?
Build an evaluation environment that embraces AI. Capture the full behavioral timeline covering prompts, decisions, and iterations. Score across multiple dimensions. You will measure thinking quality, not rule-breaking.
Stop detecting. Start evaluating.
See how Eval-X captures the full behavioral timeline of how engineers actually think. 20 minutes. No slides.
Book a Demoarrow_forward